
Représentation des caractères
Comment ça marche ?
Les caractères sont des données non numériques, ce sont des symboles alphanumériques :
les lettres majuscules et minuscules,
les symboles de ponctuation (& ~ , . ; # " - etc...),
les chiffres.
Un texte, ou chaîne de caractères, sera représenté comme une suite de caractères.
À chaque caractère correspond un nombre qui sera codé en binaire
Méthode : Le codage ASCII
Historiquement, le codage ASCII (American Standard Code for Information Interchange) a été défini et utilisé pour écrire des textes en anglais.
La table ASCII fournit la correspondance entre 128 caractères et leur représentation binaire. Les caractères sont numérotés de 0 à 127.
A priori, 7 bits suffisent à coder ces caractères, en effet 128 = 27.
En pratique, les ordinateurs travaillent presque tous sur des multiples de 8 bits, ce que l'on nomme octet.
Chacun des 128 caractères ASCII est donc codé par un octet dont le 8ème bit est à 0.
Ci-dessous on donne les représentations en binaire des caractères :
|0000 |0001 |0010 |0011 |0100 |0101 |0110 |0111 |1000 |1001 |1010 |1011 |1100 |1101 |1110 |1111 |
----+-----------------------------------------------------------------------------------------------+
0000 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
0001 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
0010 | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
0011 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
0100 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
0101 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
0110 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
0111 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |----+-----------------------------------------------------------------------------------------------+
On lit dans cette table que la représentation binaire du caractère 'a' est '0110 0001' (7e ligne, 2e colonne).
Ce qui correspond à l'écriture en binaire du nombre 97
On dit que le code ASCII de 'a' est 97
Et celle du 'z' est 01111010 soit 122
Le code ASCII de 'z' est 122
Les 33 caractères de contrôle ( les deux premières lignes et le caractère DEL) correspondent aux significations suivantes :
NUL Null (nul)
SOH Start of Header (debut d'en-tete)
STX Start of Text (debut du texte)
ETX End of Text (fin du texte)
EOT End of Transmission (fin de transmission)
ENQ Enquiry (End of Line) (demande, fin de ligne)
ACK Acknowledge (accuse de reception)
BEL Bell (caractere d'appel)
BS Backspace (espacement arriere)
HT Horizontal Tab (tabulation horizontale)
LF Line Feed (saut de ligne)
VT Vertical Tab (tabulation verticale)
FF Form Feed (saut de page)
CR Carriage Return (retour chariot)
SO Shift Out (fin d'extension)
SI Shift In (demarrage d'extension)
DLE Data Link Escape
DC1-DC4 Device Control (controle de peripherique)
NAK Negative Acknowledge (accuse de reception negatif)
SYN Synchronous Idle
ETB End of Transmission Block (fin du bloc de transmission)
CAN Cancel (annulation)
EM End of Medium (fin de support)
SUB Substitute (substitution)
ESC Escape (echappement)
FS File Separator (separateur de fichier)
GS Group Separator (separateur de groupe)
RS Record Separator (separateur d'enregistrement)
US Unit Separator (separateur d'unite)
SP Space (espace)
DEL Delete (effacement)
Remarque : Les lettres
Les lettres se suivent dans l'ordre alphabétique (codes 65 à 90 pour les majuscules, 97 à 122 pour les minuscules).
Pour passer des majuscules au minuscules, il faut ajouter 32 au code ASCII des majuscules.
Comme : 97 - 65 = 32 = 25
Cela revient à modifier le 5ème bit en binaire :
G(71)
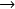 01000111 et g(103)
01010111
01000111 et g(103)
01010111
Remarque : Les chiffres
Les chiffres sont rangés dans l'ordre croissant (codes 48 à 57), et les 4 premiers bits définissent la valeur en binaire du chiffre.
00110000 0 48
00110001 1 49
00110010 2 50
00110011 3 51
00110100 4 52
00110101 5 53
00110110 6 54
00110111 7 55
00111000 8 56
00111001 9 57
Et les autres caractères ?
La nécessité de représenter des textes comportant des caractères non présents dans la table ASCII tels ceux de l'alphabet latin utilisés en français comme le 'à', le 'é' ou le 'ç' impose l'utilisation d'un autre codage que l'ASCII.
Plusieurs propositions de codage coexistent.
Afin de faciliter les choses, ces propositions sont des extensions du codage ASCII :
le codage des caractères présents dans la table ASCII est conservé ;
le principe du codage de chacun des caractères sur un octet est conservé.
Mais les 8 bits de l'octet vont être utilisés. Cela permet de coder 28 = 256 caractères, soit 128 caractères supplémentaires.
L'ISO, organisation internationale de normalisation, propose de son côté plusieurs variantes de codages adaptées aux différentes langues. La plus utilisée concerne les langues européennes occidentales. Il s'agit de l'ISO-8859-1, aussi nommé ISO-Latin1.
Microsoft propose le codage dit Windows-1252 (encore appelé ANSI, bien que cela puisse paraître abusif, l'ANSI, American National Standards Institute, n'ayant jamais validé cette table !).
Ce codage ne diffère de l'ISO-8859-1 que pour quelques caractères tels le signe euro, €, la ligature o-e, œ, ou certains guillemets qui utilisent des codes réservés par ISO-Latin-1 pour des caractères de contrôle.
Et les autres langues ?
À l'évidence, 256 caractères ne suffisant pas pour représenter les lettres de tous les alphabets utilisés (pensons au russe, à l'hébreu, etc.), un nouveau standard a été introduit : Unicode.
La table Unicode comporte la définition de près de cent cinquante mille caractères.
Le codage de cette table est multiple. Le codage le plus couramment utilisé se nomme UTF-8. Son principe est le suivant : une première série de caractères sont codés sur un octet. D'autres caractères sont codés sur deux octets.
De même des codages sur 3 ou 4 octets sont utilisés pour d'autres caractères. (Cette rapide introduction à UTF-8 est volontairement simplifiée.)
Les 128 premiers caractères de la table UTF-8 sont compatibles avec le codage ASCII. Ainsi le codage UTF-8 d'un texte ne comportant que des caractères présents dans la table ASCII sera le même que le codage ASCII de ce texte.
Ce ne sera pas vrai pour un texte ISO-Latin-1.
Il importe donc, quand on veut décoder un texte, de savoir quel est le codage utilisé sous peine de décoder improprement les caractères.
C'est pourquoi, on utilisera un encodage en UTF-8...




