
Les fichiers de données
Le format csv
Les collections de données sont souvent des fichiers aux formats csv (comma separated values), c'est à dire des fichiers textes où les données sont séparées par des virgules.
Ce qui donne par exemple :
"Prenom","Nom","Email","Age"
"Jean", "Petit", "jean@monsite.fr", "34"
"Anne", "Le Gall", "anne@exemple.net", "21"
"Pierre", "Diawara", "pierre@sonsite.com", "44"
Il existe d'autres formats ( nous le verrons plus tard...)
Ces fichiers s'ouvrent avec un tableur, cependant le célèbre Excel ne lit correctement que des fichiers csv où le séparateur est un point-virgule.
Tandis que Libre-Office-calc, lit correctement tous les fichiers.
Simulation : Observons une collection
Téléchargez et ouvrez ce fichier avec Excel et observez que l'affichage n'est pas celui que nous attendons d'un fichier de donnée...
Ouvrez-le avec Libre-office calc en choisissant un encodage en UTF-8 ( pour un affichage normal des caractères accentués )
Choix de l'encodage | 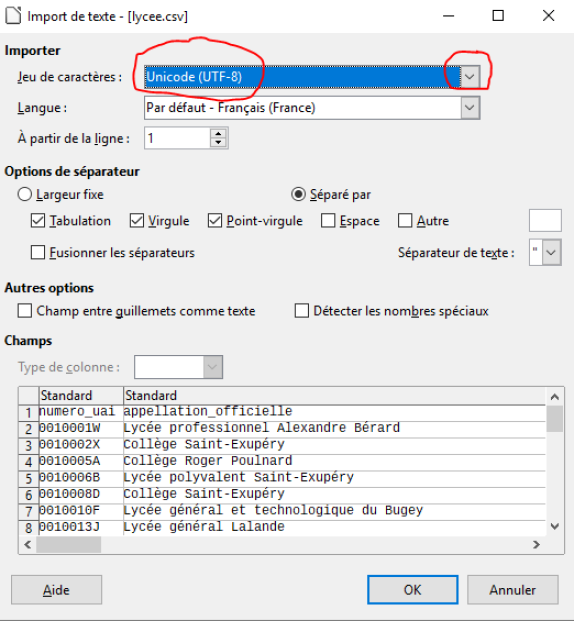 |
Il s'agit de tous les établissements scolaires de France ...
Quels sont les descripteurs ?
Combien d'établissements sont dans cette collection ?
Trouvez la ligne correspondant à votre lycée.
Trouvez la ligne correspondant à l'école où vous avez appris à lire.
Trouvez combien d'établissements se trouvent dans une ville de votre choix.
Vous avez sans doute constaté que ce n'est pas si simple d'obtenir ces informations...
Simulation : Faisons ces mêmes recherches avec un programme.
Nous travaillerons avec Processing
Téléchargez ce fichier
Ouvrez Processing en mode Python
Glissez-déposez le fichier dans Processing. | 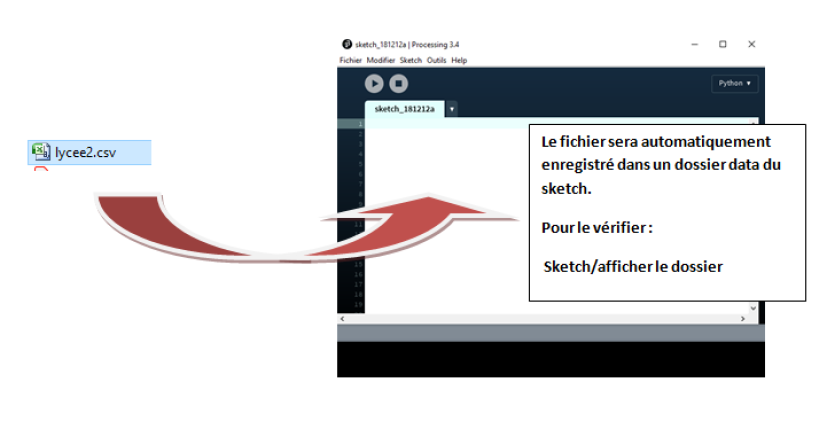 |
On écrit le code suivant :
La première ligne charge le fichier dans la variable table et précise que les éléments de la première ligne sont des descripteurs.
La seconde affiche le nombre de lignes ( donc le nombre d'établissements).
table=loadTable("data/lycee2.csv","header")
print(table.getRowCount())
Et cette ligne supplémentaire permet d'obtenir le nombre de colonnes.
table=loadTable("data/lycee2.csv","header")
print(table.getRowCount())
print(table.getColumnCount())
Faisons afficher les informations de notre lycée : Jean moulin de Draguignan.
Son numéro_uai est 0830015R.
Dans le code ci-dessous :
On trouve et on stocke dans "resultat" les éléments de la ligne qui contient ce numéro avec :
resultat=table.findRow("0830015R","numero_uai")Puis on affiche les différents éléments de cette ligne à l'aide de leurs descripteurs :
table=loadTable("data/lycee2.csv","header")
print(table.getRowCount())
print(table.getColumnCount())
resultat=table.findRow("0830015R","numero_uai")
print(resultat.getString("appellation_officielle"))
print(resultat.getString("adresse_uai"))
print(resultat.getString("code_postal_uai"))
print(resultat.getString("localite_acheminement_uai"))
Essayez avec ce numéro : 0830015S
Simulation : Et si on ne connaît pas le numéro uai
Il est fort probable que vous ne connaissiez pas le numéro uai de votre école. Vous vous souvenez probablement de la ville dans laquelle vous avez appris à lire.
Le descripteur : "localite_acheminement_uai", donne la ville de l'établissement, on va donc faire une recherche suivant ce descripteur.
Le problème c'est qu'il y a sans doute plusieurs établissements dans cette localité.
On va donc utiliser une boucle qui testera toutes les lignes de la table
De plus il va falloir comparer deux textes...et parfois le nom de la ville c'est par exemple :DRAGUIGNAN et dans le fichier il y a : DRAGUIGNAN CEDEX
On va utiliser une fonction qui compare les contenus et qui renvoie False si le nom n'est pas dans la phrase et True sinon
Les éléments de la ligne testée sont dans la variable tmp, vous devez compléter ce programme, pour qu'il affiche les informations voulues quand le test est "True"
def setup():
table=loadTable("data/lycee2.csv","header")
print(table.getRowCount())
print(table.getColumnCount())
nom="DRAGUIGNAN"
for i in range(table.getRowCount()):
tmp=table.getRow(i)
localite=tmp.getString("localite_acheminement_uai")
test=compare(localite.split(" "),nom.split(" "))
if test==True:
print("****************************************************************************************")
print(tmp.getString("numero_uai"))
# partie à compléterdef compare(phrase,mots):
for mot in mots: #pour les "mot" se trouvant dans "mots"
if mot not in phrase: #s'il ne sont pas dans la phrase
return False
else:return True
Essayez avec DRAGUIGNAN CEDEX
Essayez avec CEDEX
localite.split(" ") signifie que l'on précise que le séparateur de mot dans localite est un espace.
La variable test est en informatique ce que l'on appelle un booléen, c'est à dire une variable qui peut avoir deux valeurs : vraie ou fausse.
Complément : Corrigé
def setup():
table=loadTable("data/lycee2.csv","header")
print(table.getRowCount())
print(table.getColumnCount())
nom="DRAGUIGNAN"
for i in range(table.getRowCount()):
tmp=table.getRow(i)
localite=tmp.getString("localite_acheminement_uai")
test=compare(localite.split(" "),nom.split(" "))
if test==True:
print("****************************************************************************************")
print(tmp.getString("numero_uai"))
print(tmp.getString("appellation_officielle"))
print(tmp.getString("adresse_uai"))
print(tmp.getString("code_postal_uai"))
print(tmp.getString("localite_acheminement_uai"))
def compare(phrase,mots):
for mot in mots:
if mot not in phrase:
return False
else:return True
Simulation : Le même travail avec EduPython
Téléchargez ce fichier
Ouvrez EduPython
Dans un dossier contenant le fichier que vous venez de télécharger
Écrivez et enregistrez le programme suivant :
import csv
# chargement du fichier csv en utilisant la biblio csvwith open('lycee2.csv','r', encoding='utf-8') as f:
premiere_ligne = f.readline()
print("Les descripteurs de la collection des établissements scolaires :")
print(premiere_ligne)
dialecte_fichier_csv = csv.Sniffer().sniff(premiere_ligne)
data_lignes = list(csv.reader(f, dialect=dialecte_fichier_csv))
# on met le tout dans une listeliste=[]for ligne in data_lignes:
liste.append(ligne)
print(liste[1])
Exécutez le programme
Vous devriez voir dans la console :
Les descripteurs de la collection des établissements scolaires :
numero_uai,appellation_officielle,denomination_principale,patronyme_uai,secteur_public_prive_libe,adresse_uai,lieu_dit_uai,boite_postale_uai,code_postal_uai,localite_acheminement_uai,coordonnee_x,coordonnee_y,appariement,localisation,nature_uai,nature_uai_libe,etat_etablissement,,,,,,,
['0010002X', 'Collège Saint-Exupéry', 'COLLEGE', 'SAINT-EXUPERY', 'Public', '6 RUE AGUETANT', '', '508', '1500', 'AMBERIEU EN BUGEY', '882408', '3', '6543019', '6', 'MANUEL', 'BATIMENT', '340', 'Collège', '1', '', '', '', '', '']
Comme vous le constatez, le premier élément de chaque 'sous-listes' de la liste est le n° uai :
Faisons afficher les informations de notre lycée : Jean moulin de Draguignan.
Son numéro_uai est : 0830015R.
Dans le code ci-dessous :
On recherche avec une boucle le n° uai de notre lycée, si on le trouve on fait afficher la liste correspondante
import csv
# chargement du fichier txt en utilisant la biblio csvwith open('lycee2.csv','r', encoding='utf-8') as f:
premiere_ligne = f.readline()
print("Les descripteurs de la collection des établissements scolaires :")
print(premiere_ligne)
dialecte_fichier_csv = csv.Sniffer().sniff(premiere_ligne)
data_lignes = list(csv.reader(f, dialect=dialecte_fichier_csv))
# on met le tout dans une listeliste=[]for ligne in data_lignes:
liste.append(ligne)
#print(liste[1])# on parcourt la liste en recherchant le n° uai de notre lycéefor el in liste:
if el[0]=="0830015R":
print(el)
Travail à faire :
Faites afficher l'adresse au complet de notre lycée. ( La ville se trouve à el[9] )
Essayez avec ce numéro : 0830015S
Complément : Corrigé
import csv
# chargement du fichier txt en utilisant la biblio csvwith open('lycee2.csv','r', encoding='utf-8') as f:
premiere_ligne = f.readline()
print("Les descripteurs de la collection des établissements scolaires :")
print(premiere_ligne)
dialecte_fichier_csv = csv.Sniffer().sniff(premiere_ligne)
data_lignes = list(csv.reader(f, dialect=dialecte_fichier_csv))
# on met le tout dans une listeliste=[]for ligne in data_lignes:
liste.append(ligne)
#print(liste[1])for el in liste:
if el[0]=="0830015R":
print(el)
print(el[1])
print(el[7]," ",el[5])
print(el[8])
print(el[9])
Simulation : Et si on ne connaît pas le numéro uai
Il est fort probable que vous ne connaissiez pas le numéro uai de votre école.
Vous vous souvenez probablement de la ville dans laquelle vous avez appris à lire.
On accède à la ville avec el[9]
Le code ci-dessous :
demande à l'utilisateur le nom d'une ville
affiche le numéro uai des établissements scolaires de cette ville
import csv
# chargement du fichier txt en utilisant la biblio csvwith open('lycee2.csv','r', encoding='utf-8') as f:
premiere_ligne = f.readline()
print("Les descripteurs de la collection des établissements scolaires :")
print(premiere_ligne)
dialecte_fichier_csv = csv.Sniffer().sniff(premiere_ligne)
data_lignes = list(csv.reader(f, dialect=dialecte_fichier_csv))
# on met le tout dans une listeliste=[]for ligne in data_lignes:
liste.append(ligne)
s=input('Entrez un nom de ville:')
s=s.upper()
# On parcourt la liste et si le nom de la ville est dans el[9], on affiche les résultatsfor el in liste:
if s in el[9]:
print("================================================")
print(el)
Travail à faire :
Faire afficher les adresses complètes de tous les établissements d'une ville
Complément : Corrigé
import csv
# chargement du fichier txt en utilisant la biblio csvwith open('lycee2.csv','r', encoding='utf-8') as f:
premiere_ligne = f.readline()
print("Les descripteurs de la collection des établissements scolaires :")
print(premiere_ligne)
dialecte_fichier_csv = csv.Sniffer().sniff(premiere_ligne)
data_lignes = list(csv.reader(f, dialect=dialecte_fichier_csv))
# on met le tout dans une listeliste=[]for ligne in data_lignes:
liste.append(ligne)
s=input('Entrez un nom de ville:')
s=s.upper()
for el in liste:
if s in el[9]:
print("===============================================================")
print(el[1])
print(el[7]," ",el[5])
print(el[8])
print(el[9])




